UX LEAD CASE STUDY · DECISION SYSTEMS · INCIDENT OPERATIONS
Designing Decision Authority
Under Pressure
How we redesigned who gets to decide — and when — inside high-stakes SaaS incident operations.
02:47 AM — The Decision Nobody Wants to Make
It is 02:47 AM. A "Latency Degraded" alert fires for the payment gateway. The on-call engineer is alone. Customer support is silent—no tickets yet. But the dashboard shows a 12% drift in response times, just below the automatic paging threshold.
The engineer faces a critical operational trade-off. Escalation prevents potential data loss but risks a false positive. Silence protects the team from fatigue but risks a major outage. The system forces a human to resolve this signal ambiguity without sufficient data.
Incident Management Is Not a Messaging Problem
Incident management is often reduced to 'ChatOps'—a tooling problem. However, tools cannot resolve the fundamental conflict of distributed truth. When metrics, customer reports, and engineering logs disagree, the system forces humans to synthesize reality under duress. This is an impossible cognitive load.
- Payments feel slow SIGNAL
- Intermittent login failures SIGNAL
- Support chat spike NOISE
- p95 latency +12% SIGNAL
- Error rate: normal NOISE
- DB latency spike SIGNAL
- Deploy 40 min ago SIGNAL
- Migration window active NOISE
- No config change NOISE
Who This System Is For
Primary User: The On-Call Engineer (SRE/DevOps). They hold the pager and the liability. They are often sleep-deprived and socially pressured to avoid false positives.
Stakeholders: Engineering Leadership (VP/Director) who demand uptime, and Customer Success teams who demand transparency. The tension between these groups defines the decision space.
The Real Problem: Hero Culture and Decision Avoidance
We observed a consistent pattern of 'Hero Culture' masking systemic failure. Engineers would manually suppress valid alerts to 'save the team' from interruption, absorbing the risk personally. This decision avoidance was rational: the reputational cost of crying wolf was higher than the cost of a delayed response. The system needed to remove this social calculus.
“Is this a systemic failure or a transient anomaly?”
Design Goals
- Eliminate Ambiguity. A state is either 'Normal' or 'Incident'. No 'Watching'.
- Shift Liability. The system, not the human, declares the status based on pre-set thresholds.
- Enforce Protocol. Mandatory escalation paths. No skipping steps to 'just fix it'.
Principles That Shaped the System
- Authority must be explicit, not derived.
- Silence is a valid state; noise is a failure mode.
- The burden of proof belongs to the system.
The System That Decides
We rejected full automation because context matters. A database migration looks like an outage to a metric, but is expected behavior to an engineer. The system does not decide for the human; it gates the options available to the human. It ingests conflicting signals and presents a unified 'Candidate State' that must be confirmed or rejected.
Role-Based Authority
We redistributed decision rights to align with signal fidelity. The Customer owns 'Perception' (impacting triage priority). The Platform owns 'Metrics' (triggering candidates). The Engineer owns 'Remediation' (confirming reality). This stripped leadership of the ability to 'override' a technical incident based on gut feeling, creating significant initial friction.
The Decision Surface
The interface is strictly hierarchical. Real-time metrics are subordinated to 'Decision Cards'. We intentionally hid raw log streams during the 'Triage' phase to prevent analysis paralysis. The 'Declare Incident' action is irreversible by design—once triggered, it initiates a legal and compliance chain that cannot be undone, forcing a deliberate commitment.
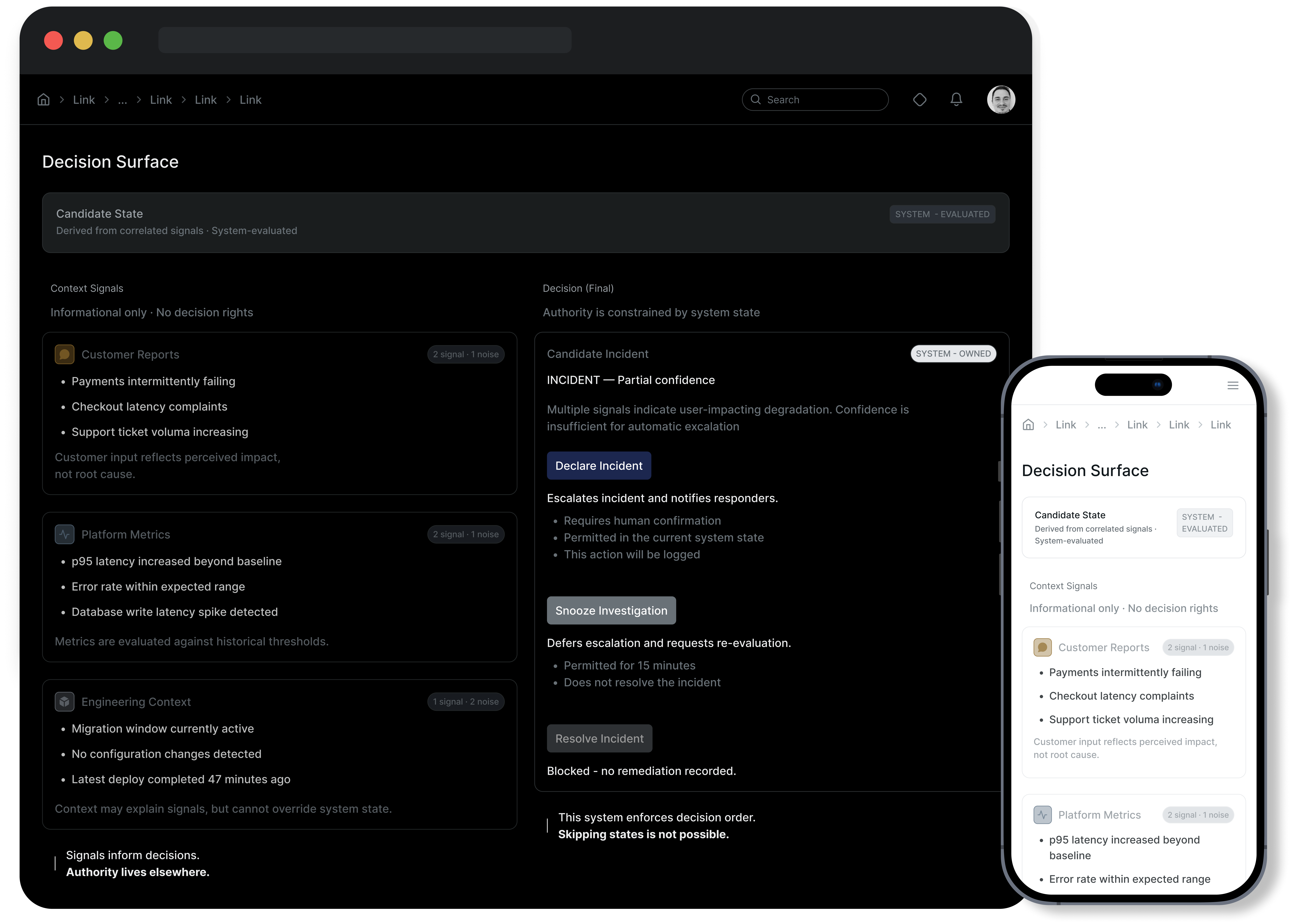
The Decision Moment: Snooze vs Declare
The 'Snooze' action is not a pause; it is a declaration of safety. Snoozing a valid incident silences the alarm for 4 hours, during which a minor degradation can spiral into data loss. 'Declare' immediately pages executive leadership. We clarified the stakes: falsely snoozing is a dereliction of duty; falsely declaring is merely a process error.
Proof: The System Mechanics
The logic is governed by a strict Finite State Machine. An engineer cannot jump from 'Alert' to 'Resolved' without passing through 'Investigation' and 'Remediation'. This friction prevents the common anti-pattern of 'ghost fixing'—resolving an issue without documenting the root cause.
Impact
Impact here wasn’t about speed. It was about making decisions predictable instead of person-dependent.
- Clearer postmortems
- Reduced reliance on individual heroics
My Role
I owned the core decision framework and the role-based authority model. I specifically decided to hide raw logs during the "Triage" phase to force binary decision-making, a choice that initially generated significant friction with senior engineering leads. I accepted the risk that this constraint might delay root cause analysis in edge cases, arguing that the reduction in decision paralysis was the higher-value outcome.
Reflection
Designing for authority requires removing the comfort of ambiguity. It forces teams to confront their own broken processes. This system did not just clean up the UI; it exposed and corrected the political power dynamics of incident management.